Big O Notation 的作用
对于二叉搜索树的高度,我们可以说:
- 他们在最坏的情况时的高度是 Θ(N)
- 他们的高度是
- 他们的高度是
对于上述三种表述方式,最佳的表述方式其实是:最坏的情况时的高度是 Θ(N),这样的表述会更加精准。
在某些大家都互相明白的场合下,也可以说他们的高度是
此外,BST 的最好情况的高度为 Θ(log N)
二叉搜索树的深度
高度:
- 下面的 BST 的高度为 4
- 在最坏情况下:
- 最多需要进行 5 次比较操作(height + 1)
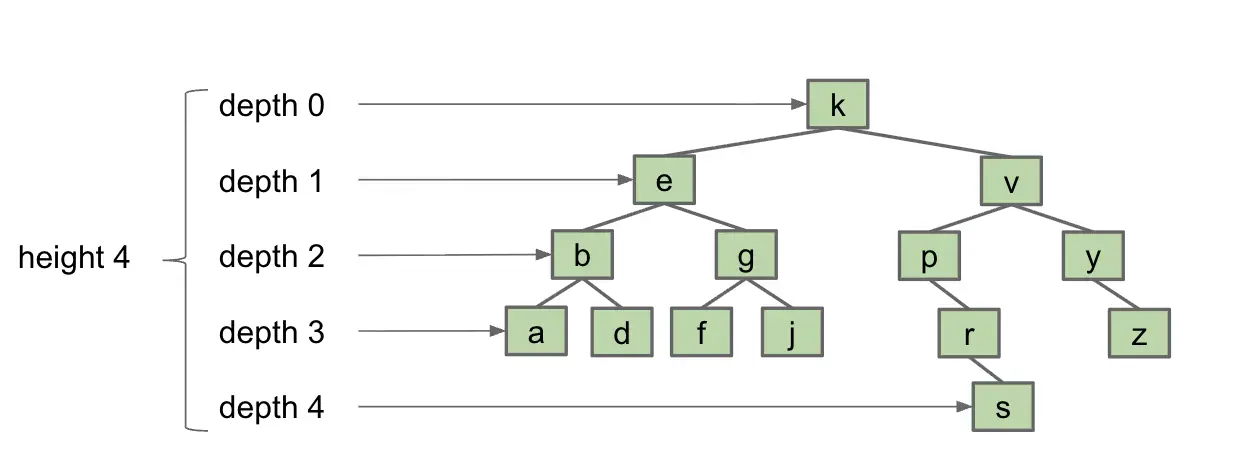
- 最多需要进行 5 次比较操作(height + 1)
平均深度:
- 计算方式:
- 在平均情况下:
- 平均需要进行 3.35 次比较操作(average depth + 1)
随机插入数据:
他们的高度期望/通常为 Θ(log N),但不能保证总是
B-trees / 2-3 trees / 2-3-4 trees
BST 的问题:
BST 在数据随机插入时性能很好,但现实中数据通常是按时间顺序逐渐到来的(比如时间戳),无法保证随机性,这会导致 BST 退化、性能变差,因此需要寻找新的方法来解决这个问题。
改进:
- 为保持树的高度不变,可以向某个叶节点中添加多个数据
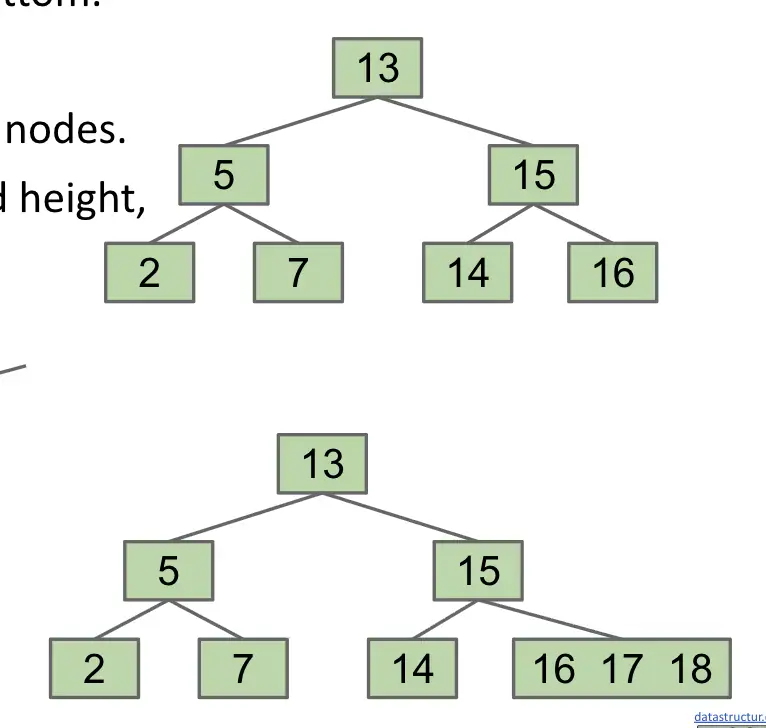
进一步改进:
- 问题:
- 某个叶节点中可能包含太多的数据,检索效率太慢
- 因此,可以设置一个最大值 L(不大于 3):
- 如果任何节点中的项数量超过 L 项,则移动中间 key 到父节点。
- 接着,原节点分裂成左右两个节点;
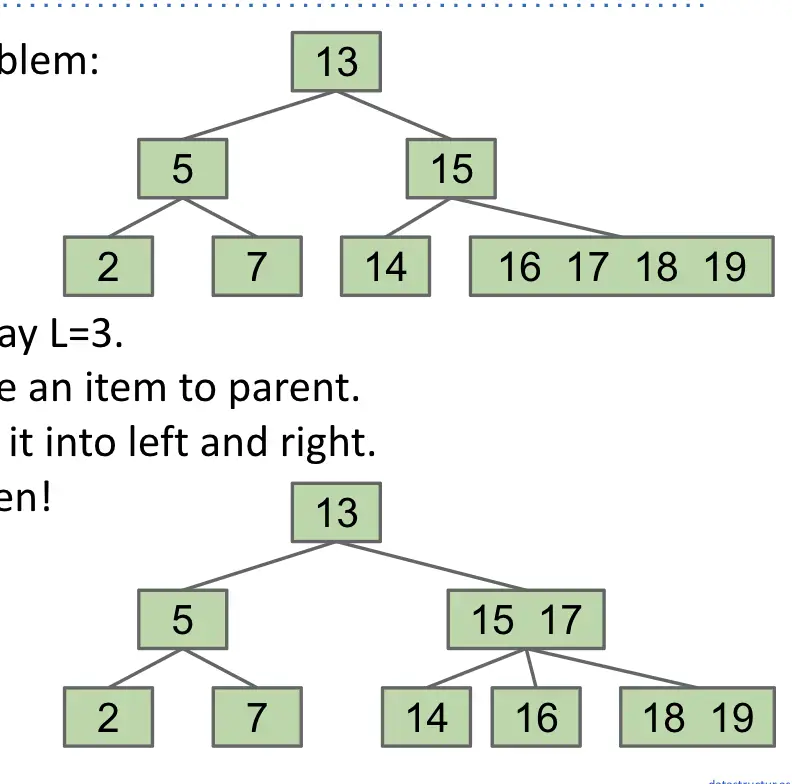
如果根节点也超过了最大值 L:
模仿上述操作,将已满根节点的一项移至上方,作为新的根节点
当 L = 3 时,B Tree 也被称为:
- 2-3-4 tree
- 或 2-4 tree
- 其中“2-3-4”表示每个节点可以有 2、3 或 4 个子节点
当 L = 2 时:
- B 树也被称为 2-3 树(2-3 tree)
B tree 的两个重要性质
B 树的构造方式必须满足:
- 所有叶子节点到根的距离相同
- 非叶节点若有 k 个元素,则必须有 k+1 个子节点
B tree 的时间复杂度
B tree 的运行时间总是 ,无论 contains 或 add 操作