集合的改进
Data Indexed Arrays
设计:
- 创建一个大小为 20000 数组,每个索引位置只保存 True 或者 False
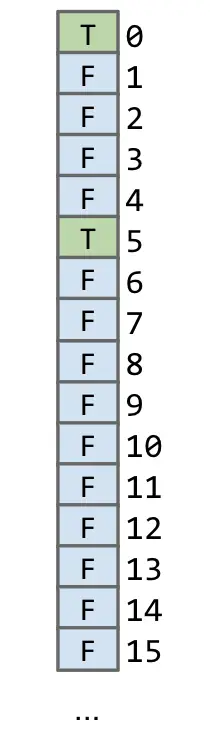
运行时间: Θ(1)
问题:
- 浪费了很多内存
- 只适用于存数字的情形,无法适用于字母等
DataIndexedEnglishWordSet
避免冲突:
- 通过某种计算法则,将字符串转换为数字

问题:
- 只能存放纯英文内容,不能包含标点符号或者汉字
DataIndexedStringSet
ASCII 表:
- 大多数计算机所使用的最基本的字符集是 ASCII 格式。
- 每个可能的字符都被赋予了 0 到 127 之间的一个值。
- 通过将某个字符所处 ASCII 表中的编号乘以以 126 为底的一个数即可
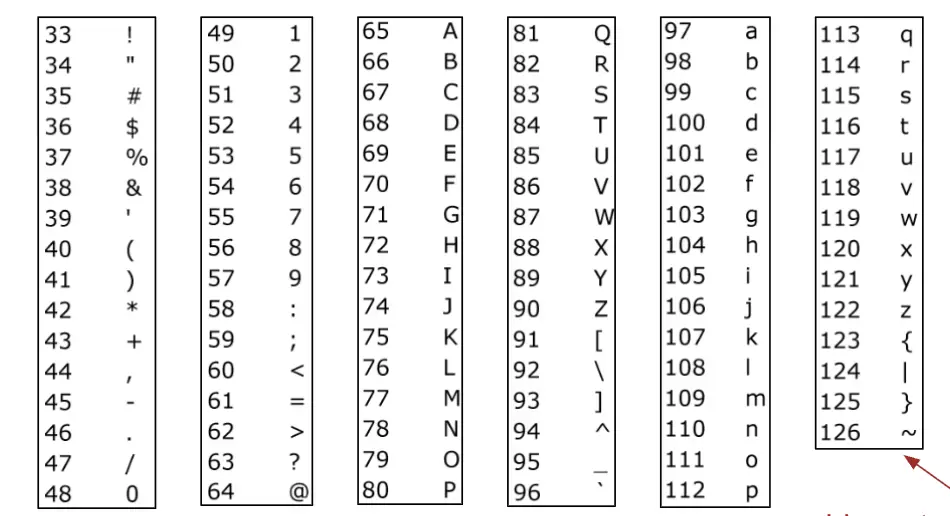
除 ASCII 表以外的中文字符:
- 英文以外的字符存放在Unicode表中
通过 ASCII 表和其他表即可计算出每个字符串独特的数字表示形式,并作为索引添加到数组中
Integer Overflow
Java 中 int 支持的最大数字为2,147,483,647,当超过了这个值,就会变成另一边的负数 -2,147,483,648
因此,会存在若干个字符串的数字表示形式是相同的,这会造成冲突,需要用哈希表来进一步改进
Hash Tables
Hash Tables 实现步骤:
- 数据被转换为一个哈希码
- 然后,该哈希码会被简化(通常通过取模运算)为一个有效的桶的索引
- 接着,数据会被存储在与该索引相对应的桶中
- 当负载因子 N/M 超过某个常数时,会进行扩容(N 为数据的数量,M 为桶的数量,扩容以确保平均运行时间是常数级别)
- 如果数据分布得当,平均运行时间将为 Θ(1),最坏情况下可能退化为 Θ(N)
整体数据结构称为 hash table,数组的每一项称为桶(bucket),桶中包含多个数据项。
桶中的数据项在 Java 中通常以链表形式存储,元素较多时会转换为红黑树。
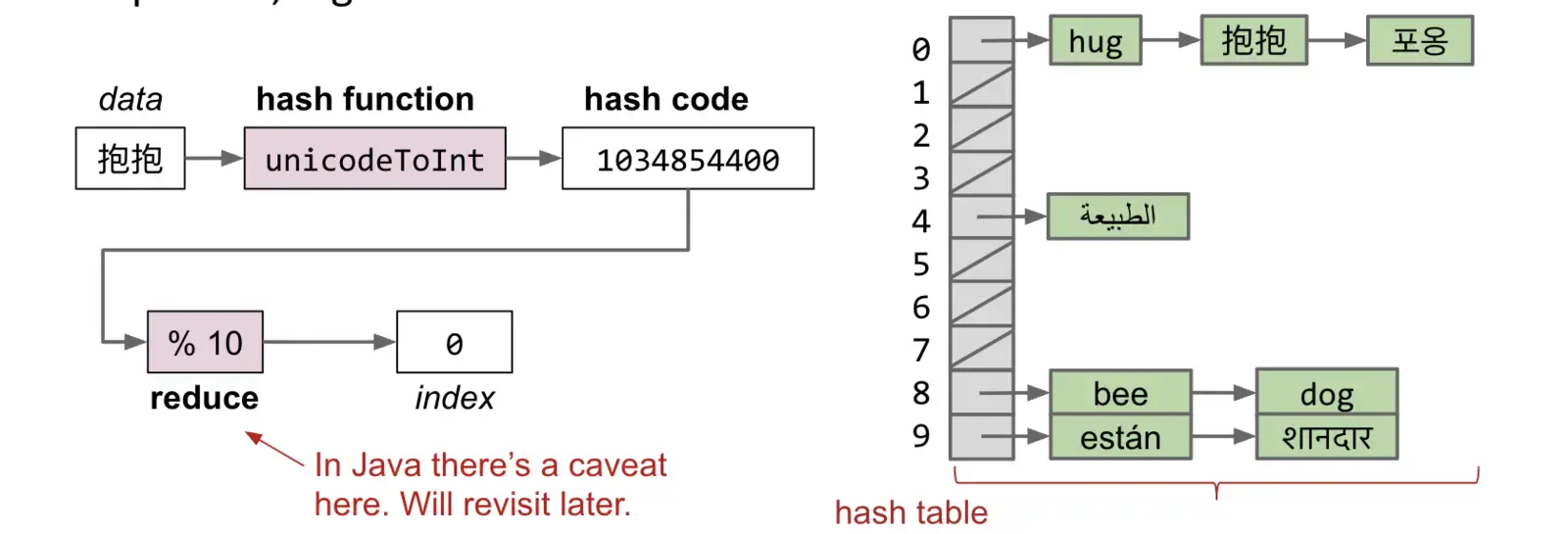
上图中展示的数据仅包含 key,这被称为 HashSet;如果每个数据由键值对组成,则被称为 HashMap。
当用户需要查找某个 key 是否存在,或查找某个 key 对应的 value 时,需要经过以下步骤:
- 将 key 转换为哈希码,并通过运算映射为一个桶的索引值
- 在对应索引的桶中遍历,直到找到相同的 key