BFS(广度优先搜索)
BFS 使用 queue 来管理还需要处理的节点,这个 queue 被称作fringe,指是当前“已经发现,但还没完全处理”的节点集合。
基本步骤:
- 初始化一个 queue
- 把起点
s加入 queue - 标记
s为 visited / marked
- 把起点
- 当 queue 不为空时:
- 从 queue 前端取出一个节点
v - 检查
v的所有邻居n - 如果
n没有被标记:- 标记
n - 设置
edgeTo[n] = v(含义见上节) - 如果需要记录距离,设置
distTo[n] = distTo[v] + 1 - 把
n加入 queue 的末尾
- 标记
- 从 queue 前端取出一个节点
含义:
queue保证先进入的节点先被处理- 因此 BFS 会自然地按“距离起点的层数”向外扩展
BFS 的应用:找到某个演员和某个演员演过的电影之间的关系;但不适合导航,因为现实中的道路有 weight,而 BFS 只适合于无 weight 的图
Graph 的具体实现
图算法需要两层东西:
- Graph API:决定外部怎么使用图
- 底层数据结构:决定图在内存中怎么存
选择不同的表示方式,会影响:
- runtime
- memory usage
- 图算法实现难度
1. Adjacency Matrix
定义:
用一个二维矩阵表示图中顶点之间是否有边。
如下图所示,1 代表有边,0 代表无边。对于无向图,一条边会在矩阵里出现两次
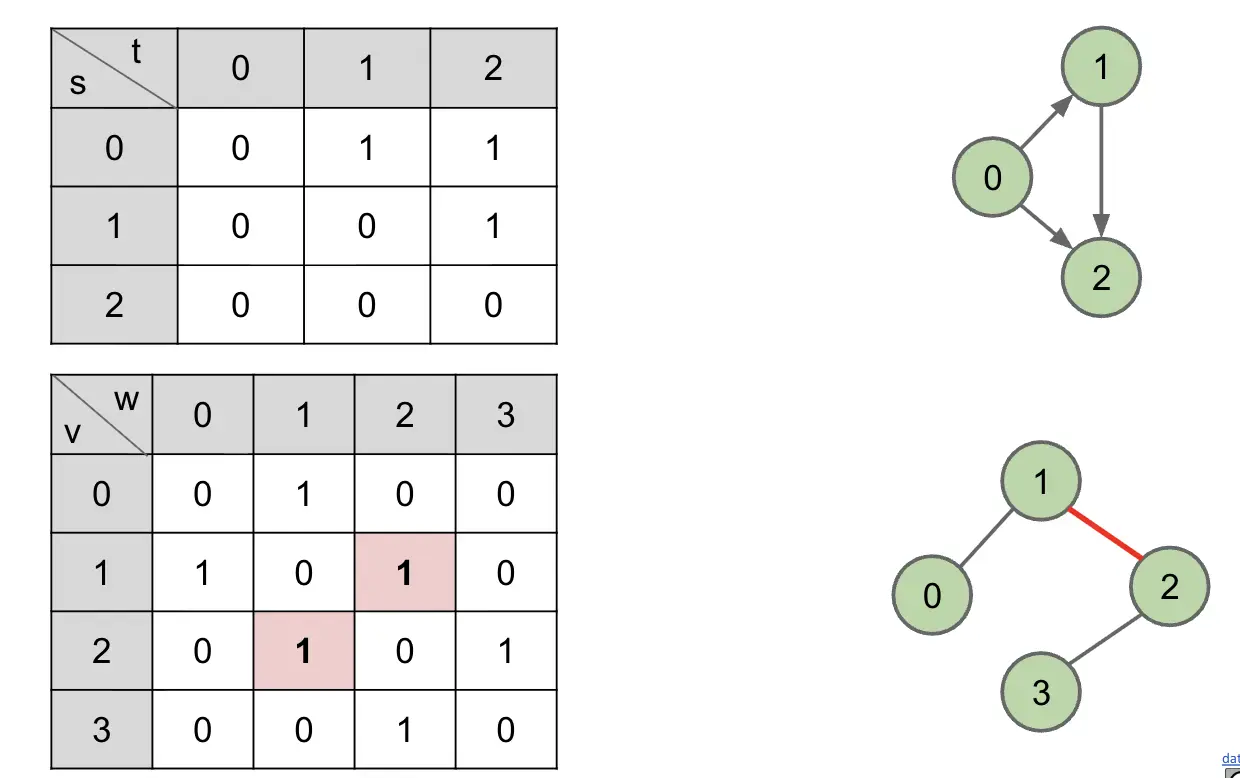
特点:
hasEdge(s, t)很快- 即使图很稀疏,也需要保存整个
V × V矩阵;遍历某个点的邻居时,需要扫描一整行; - 遍历一个点所有邻居的时间是 Θ(V)
print的运行时间为 Θ(V²)
2. Edge Sets
定义:
Edge Sets 是把所有边作为一个集合保存。

含义:
- 图被看成“一堆边”
- 适合直接保存所有边
- 但如果要找某个顶点的所有邻居,可能要检查很多边
3. Adjacency List
定义:
用一个数组保存每个顶点的邻居列表
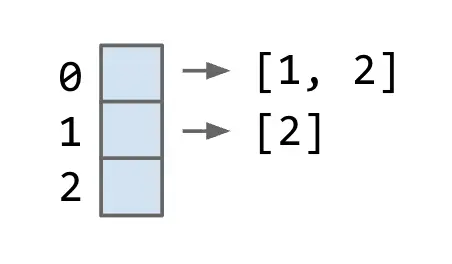
特点:
- 图实现中最常见
- 尤其适合 sparse graph
运行时间:
print的 runtime 是 Θ(V + E)
额外说明:本文笔记的结构有待完善